




Global digitalization not only makes routine life more convenient and provides new channels for financial flows but also opens new space for fraudsters.
The number of fraud victims is increasing, as well as the amount of stolen money. It is not obvious because now criminals only need to get access to the personal account; they no longer require to counterfeit or steal personal documents. Fraud concerns not only physical persons but also different kinds of organizations, for example, banks. Mostly, customers would change their bank if they face scams. Often scams are not easy to notice, and large financial enterprises need about 40 days for fraud detection, as Javelin Strategy & Research shows.
So, the main task for a company is to identify and process requests in real time and enhance the accuracy of fraud detection. If there are no data scientists or developers in your company’s staff, you should turn to experienced specialists for consulting or developing a required solution.
How does fraud detection work?

Recently the popularity of the machine learning approach to fraud detection has increased, and, as a result, the interest in the rule-based fraud detection systems has fallen. Let’s consider them in detail and compare their principles of work.
Rule-based approach
Companies can identify financial fraud by obvious signs: large transactions that happen in strange locations seem suspicious. The rule-based approach allows using special algorithms that launch manually written scenarios of fraud detection. These scenarios are straightforward and created by fraud analysts: they are based on about 300 transaction rules. Manually written scenarios require manual adjusting, and they can fail to detect hidden relations.
Rule-based systems usually work with legacy software that doesn’t provide real-time data processing that is crucial for the digital sphere.
Machine learning-based approach
The ML-based approach can detect light and hidden actions in customer’s behavior that are not evident signals of possible fraud. With the help of machine learning, specialists can build well-working algorithms that process large datasets with a lot of variables. These algorithms help identify hidden correlations and detect fraud.
ML-based systems perform data processing much faster than rule-based systems and require less manual customization. It becomes possible with a combination of smart algorithms and behavior analytics: with these two pillars, the process of verification goes faster.
Despite the obvious benefits of the ML-based system, rule-based systems are still marketplace leaders.
There is a different situation among the most powerful financial institutions: they turn to ML-based learning technologies and successfully use them against fraudsters.

For example, MasterCard uses machine learning and artificial intelligence to track and process information about transaction size, time, device, and purchase data. The system analyses account behavior during every operation and then gives real-time resolution about the transaction. This project helps to reduce the number of false declines in merchant payments, the biggest area for fraud in the financial sphere. Due to false declines, merchants lose about $118 billion per year, and customers lose about $9 billion per year.
Fraud detection is the vital goal of the banking and payment industry.
Financial giant, Feedzai, says that a properly customized machine learning process can identify about 95% of fraud cases. With this approach, companies can reduce costs for manual checking, and this is 25% of all fraud expenditures.
Capgemini claims that ML-based fraud detection systems cut fraud searching time by 70% and increase detection accuracy by 90%.
How can companies detect fraud scenarios?
Insurance claims analysis
The insurance sphere seriously suffers from fraud, even though companies give a lot of attention and spend a lot of time assessing a claim. The most widespread situations are property damage, car insurance scams, and fake unemployment claims. The way of successful confrontation is the usage of proper data sets and correct fraud detection models.

Fake claims
Machine learning allows specialists to make semantic analysis and analyze both structured and unstructured data. With its help, they can detect fake or falsified claims. For example, in the case of car insurance, machine learning algorithms analyze and search inconsistencies in agents, customers, and policy files. Rule-based systems can’t catch all hidden hints and important evidence in textual data, so analyzing claims is the most prospective way of using machine learning.
Claims duplicating and overestimating the repair value
Machine learning-based systems can also detect claims duplicates or discrepancies in the car repair cost. This problem can be solved with the help of data classifying in the repair claims and analyzing the behavior of repair services, clients, or insurance agencies. It looks suspiciously when a repair company provides its services with an overvalued price for a certain agent’s clients.
Wipro conducted research on insurance claims with the usage of artificial intelligence.
The company considered four datasets that included various characteristics: vehicle type, customer gender, marital status, the kind of license, the kind of damage, loss date, claim date, police notification data, repair costs, insured costs, market price, etc.
Preliminary conclusions of the study:
- If the injured party doesn’t report about the incident to the police, it is most likely a case of fraud.
- Old cars become a fraud subject more frequently than new ones.
- If the accident happens during the holidays, 80% that it is a case of fraud.
- As a rule, fraud cases involve third-party objects, legitimate claims don’t.
During the Wipro’s research specialists used 5 different machine learning algorithms that showed a diverse level of accuracy:
- Modified randomized undersampling: 79%
- Adjusted random forest: 73%
- Adjusted minority oversampling: 59%
- Modified multivariate Gaussian: 53%
- Logistic Regression: 38%
Anti-fraud solutions in the healthcare sphere
There are a lot of fraud cases in the sphere of healthcare and medical insurance: its complicated process includes a lot of approvals, verifications, and paperwork. So, the most popular fraud cases are fake claims with false social security numbers, claims duplication,
bills for unnecessary medical tests, fake diagnosis. These incidents are about both medical centers (they risk being involved in the drug schemes) and insurance carriers (they can lose money).
So, how can machine learning help with these fraud cases?

Fraud with the upcoding and abusing
This kind of scams is related to the case when healthcare workers charge the customers or insurance carriers bills with overstatement.
A solution to this problem is the implementation of digital analysis, created on Benford’s Law. Such analysis can define wrong digits, procedure’s upcoding, and other typical fraud.
The machine learning approach is not necessary in this case, but it can enhance the system and simplify the bureaucratic process. For example, employees can use image recognition techniques to digitize paper documentation that will be needed for analysis.
Medical bills and receipts
Insurance carriers can use the approach of summing up numerical values to check legal restrictions and define suspicious connections between medic and patient: for example, it can be exceeding the limitations to some kinds of medicine. If insurance carriers regularly use this approach, they can prevent fake total amounts.
Personal identity
Medical centers can avoid scams with the personal identity of the patient with the help of image recognition algorithms. With machine learning, they can use face and fingerprint recognition. It is needed for maintaining order in the medicine turnover.
Fraud cases in ecommerce
There are a lot of riskiest places in ecommerce. The most common fraud cases are identity theft and merchant scams.

Identity theft
This is the case when a scammer violates the customer’s account, changes personal data, and tries to get products or money as a refund from the merchant. Behavioral analytics can solve this problem and detect the fraud. Smart algorithms identify suspicious activity, make an analysis, and find a discrepancy in historical sets of personal data.
Merchant scams
This kind of fraud is popular on ecommerce platforms. Scammers can write fake reviews for their products to attract customers, since reviews can help them to choose the online store. Machine learning algorithms provide sentimental and behavior analysis and detect suspicious activity connected with merchants and their products.
Detecting fraud in banking and credit card payments
Payments are the weakest and riskiest place in the financial industry, especially when banks are forced to reduce the number of verification stages. It is the result of the increasing competition for the best customer experience and the growth of mobile payments. In this situation, banks should turn to data analysis, machine learning, and AI methods.
Let’s consider what types of fraud banks can face with payment processes.

False information
The ML-based system can estimate data credibility and find missing values in the transactions. These algorithms help to reconcile papers and system data without human presence.
So, verification of personal data via common places and transaction history can be enough for fraud detection.
Duplicate transactions
This is a widespread type of fraud when a scammer creates copies of transactions or close to the original transactions. It seems suspicious when the company bills a counterpart twice and sends the same invoice to different branch offices.
Rule-based systems can’t distinguish random mistakes from fraud cases: for example, customers can click the submission button twice or buy two times more products than usual. So, it is important to detect fraud duplicates and human mistakes.
Machine learning approaches can enhance the accuracy of results, while duplicated testing can be implemented with the usage of conventional methods.
Accounts theft and uncommon operations
Detection of these kinds of fraud is implemented with the help of the analysis of the customers’ behavior during the transaction.
Let’s model the situation: The customer goes to a certain supermarket every evening at the same time. The supermarket is near the customer’s house, and the average payment for goods places between $10 and $40. Every two days the customer comes to the gas station.
If only the system detects transactions in an unusual place of the city, for instance, in the bar, and its cost is more than $40, the system interprets it as suspicious. In this case, the system sends the verification request to the card’s owner.
The behavior analysis can use different descriptive stats: averages, standard deviations, high/low values. With these rates, the system can compare transactions and find rejections.
Fraud cases in loan applications
The lending sphere also suffers from scammers that can steal personal data. In our social network, they can get access to the ID, photos, mobile phone numbers, and addresses. It is a complicated situation for financial institutions: fraudsters become more clever, and customers don’t want to wait for a long time.

Counterfeit of personal data
Scammers provide fake personal information with spelling mistakes, wrong income, or credit qualifications. These circumstances make debt collection more difficult, but there are two ways to solve such a problem.
The company can consider a customer relationship with the bank and start checking for inconsistencies in the record fields with the special API. In this case, it is needed a scoring model for creating or calculating fraud probability. These approaches help to estimate and define fraud applications. Machine learning and enhanced analytics classify groups of applications and hence solve fraud detection problems.
With these solutions, companies can concentrate on the examples of risky credits and differentiate scammers from bad borrowers. It reduces companies’ costs and provides better credit statistics.
An Experian and European bank case report demonstrates the advantages of scoring systems:
- When the company concentrates on the 5% of applications, it can detect 52% of fraud.
- Ml-based analytical systems perform 9 times better than portfolio average.
Using machine learning for anti-money laundering

Banks, investment organizations, and other financial institutions often provide monitoring and conduct studies about money laundering cases; they need to share information about suspicious actions with each other.
For example, Dr. Miguel Agustín Villalobos and Dr. Eliud Silva in their research tell about an interesting experiment with the machine learning model. The process of learning combined the dataset of scammer’s transactions and a rule-based approach. As a result, this model can help small and midsize banks: it detects hidden connections between money transfer and fraud activity (99.6% of operations) and reduces the number of registered operations from 30 to 1.
What are the most popular and efficient fraud detection approaches?
Let’s consider how developers create effective machine learning applications for fraud detecting and what are the most common approaches that are implemented for this task.
Anomaly detection
Anomaly detection approach is one of the most frequently-used ways of fraud detection in data science. It is built on splitting all data into two groups: normal distribution and outliers.
Outliers are suspicious, unusual cases that are considered as potential fraud.
Analyzed data can include different kinds of objects, for example, transaction details, images, unstructured texts, etc. With the results of such analysis, anomaly detection algorithms can answer these questions:
- Is the customer’s access to services carried out in the usual way?
- Are the customer’s actions normal?
- Are the transactions standard?
- Are there any discrepancies in customer’s data?
Anomaly detection is a simple approach that operates with binary answers. It is not enough to complete fraud detection, but it can be useful in some cases as an auxiliary tool. For example, if the transaction seems uncommon, the system can ask for validation.
Let’s consider more complicated fraud detection approaches based on several ML algorithms and mathematical models.
Progressive fraud detection systems
Progressive fraud detection systems can better detect scam scenarios, and they are not limited to anomaly detection.
Fraud detection systems commonly use two kinds of ML-based approaches: unsupervised and supervised machine learning. They can work together or can be used as a basis for more complicated anomaly detection algorithms.
- Supervised learning uses labeled historical data: datasets have marked target variables, and the main goal is to make the system predict these variables in future data.
- Unsupervised learning models process non-marked data and split them into various clusters. It allows the system to detect hidden collections between data variables.
By mixing these approaches, you can create a proper system of fraud detection. Let’s consider its steps.
Data labeling
Manual data classifying can be a difficult process, so data scientists use models of unsupervised learning to data splitting into clusters including all hidden relations. Such a way of data labeling is exact and credible: the final dataset contains elements not only with the label “fraud” or ”no fraud” but also with small nuances in various fraud actions.
Training a supervised model
The next step after data labeling is the usage of this dataset for training supervised models. Later, such models can detect fraud transactions in industrial use.
Ensembling models
Ensembling models let data scientists make forecasts about fraud more clear. It is a standard practice to combine several models: a single model can detect some markers but lose others. So, data scientists can create several models using the same approach or mix different approaches. All models make an analysis of the transaction, after comparing their results and “voting” for a final decision.
Setting an express verification
Using ensemble models is a complicated and time-consuming process that requires the exploitation of large computing resources. So, there is no need to check all transactions this way. It seems clear to provide transaction verification in two steps.
- The first step is a simple anomaly detection or other methods of splitting transactions into regular and suspicious. This kind of verification is called express verification.
- After that, the system approves regular transactions and sends the suspicious ones to ensembling verification.
What are the strengths and weaknesses of the supervised fraud detection methods?
There are several standards for fraud detection systems:
- fraud detection in real time;
- searching for hidden connections;
- analysis customers behavior;
- high data credibility.
Though fraud detection systems can use various machine learning algorithms, they also require rule-based methods, for example, checking legal limitations for operations with cash.
Let’s take a deeper look at the most popular supervised fraud detection methods that can be used in creating ensembles of ML-based models.
An ensemble of a decision tree (random forest)
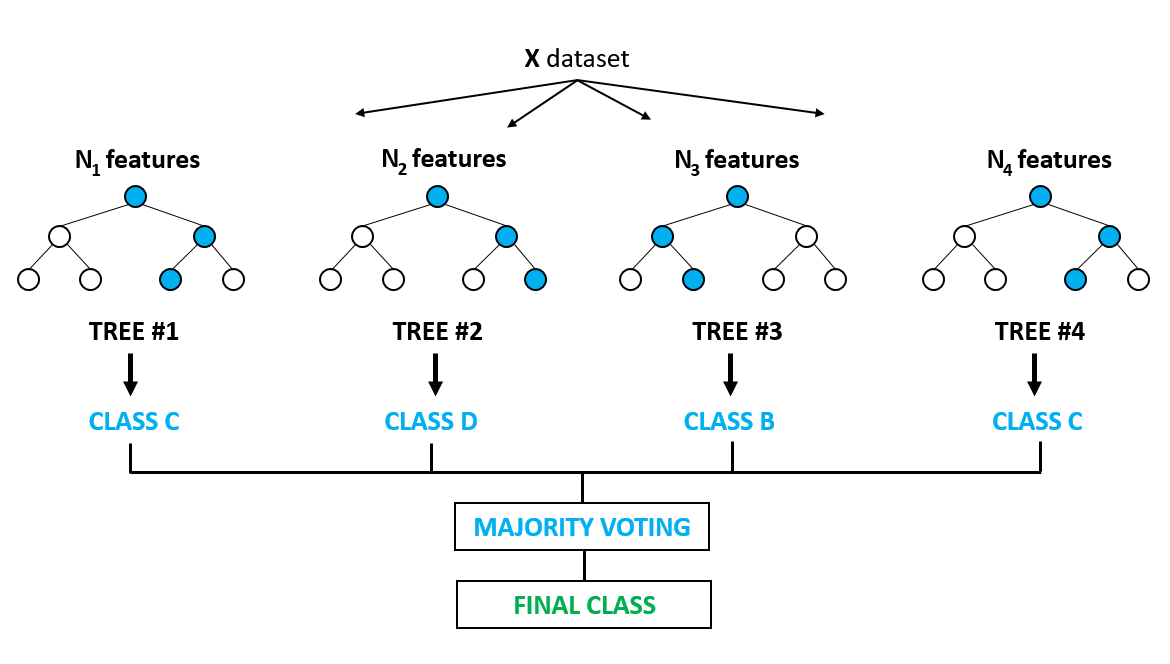
Source: Medium.com
This algorithm creates decision trees that are used for the classification of data objects. A decision tree is based on splitting several times the variable that was chosen by the model. For more clear predicting, data scientists train several decision trees on the random subsets from a common dataset. These decision trees define if a transaction is a fraud or not. The group of decision trees is called a random forest.
Random forests are frequently used for fraud detection in payment systems; they are one of the most simple ways to do this.
Benefits:
- Simplicity and speed are the main features of random forests.
- They can be used for work with different data types: credit card numbers, dates, IP addresses, etc.
- They are effective even for working with incomplete data sets.
Drawbacks:
- Sometimes there can be problems with overfitting: a model remembers plentiful patterns from training datasets and this fact prevents it from making forecasts about future data.
- Problem with dataset balance: if the dataset contains primarily regular transactions and a small part of fraud ones, the accuracy of the model’s results can go down.
Support vector machine (SVM)
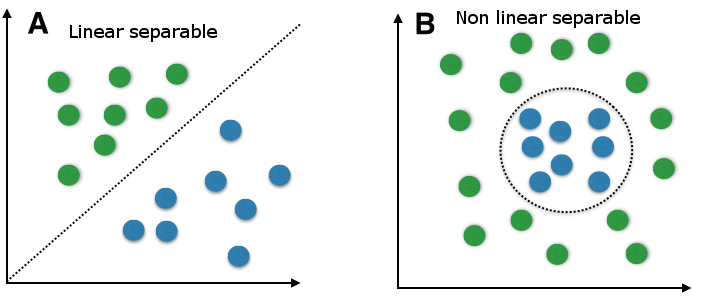
Source: Medium.com
This model applies a non-probabilistic binary linear classifier to gathering records in datasets. As the name suggests, SVM splits data into two clear parts. Building several hyperplanes in multidimensional space helps to define a vector. After splitting, the algorithm chooses the hyperplane that shows better results.
This approach is not as good as a random forest when it comes to credit card transactions, but it achieves strict results in case of large datasets.
Benefits:
- SVM shows exact results in working with multidimensional systems.
- There is no overfitting problem as in the case of a random forest.
- SVM usage simplifies the process of detecting fraud with credit cards.
Drawbacks:
- A proper SVM customizing is a long and complicated process that requires a lot of engineering time and effort.
- SVM works slowly and provides heavy computations, so there is a need for powerful computing architecture.
K-Nearest neighbors
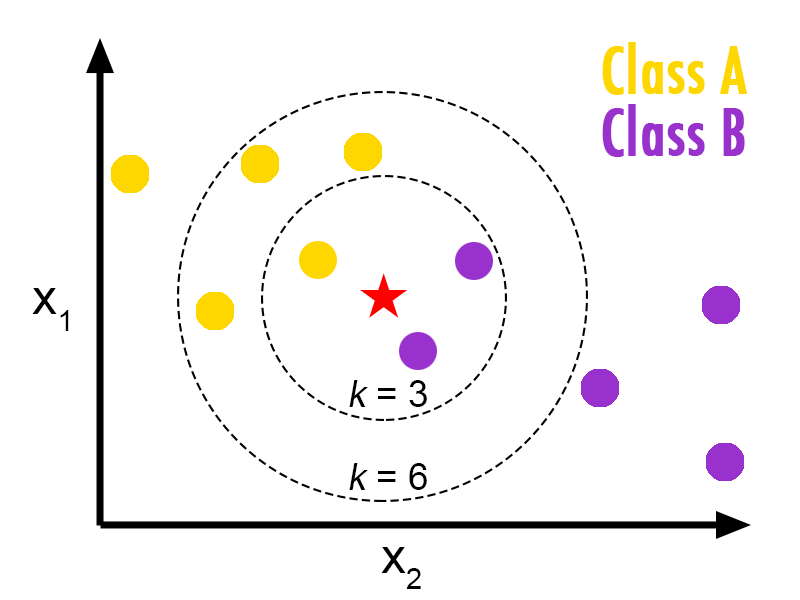
Source: Medium.com
K-Nearest neighbors classified records based on the distance in multidimensional space. With this algorithm logic, the record becomes one among the class of nearest neighbors.
Every existing record from the cluster “votes” for every new record using the distance parameter.
This approach is also popular in analyzing credit card transactions.
Benefits:
- K-Nearest neighbors approach can work with missed and noisy data, so data scientists can customize large sets and spend little time on this.
- It doesn’t require a lot of engineering effort to tweak models.
- It provides strict results.
Drawbacks:
- K-Nearest neighbors need a powerful infrastructure.
- This approach shows a lack of interpretability.
Neural networks and deep neural networks
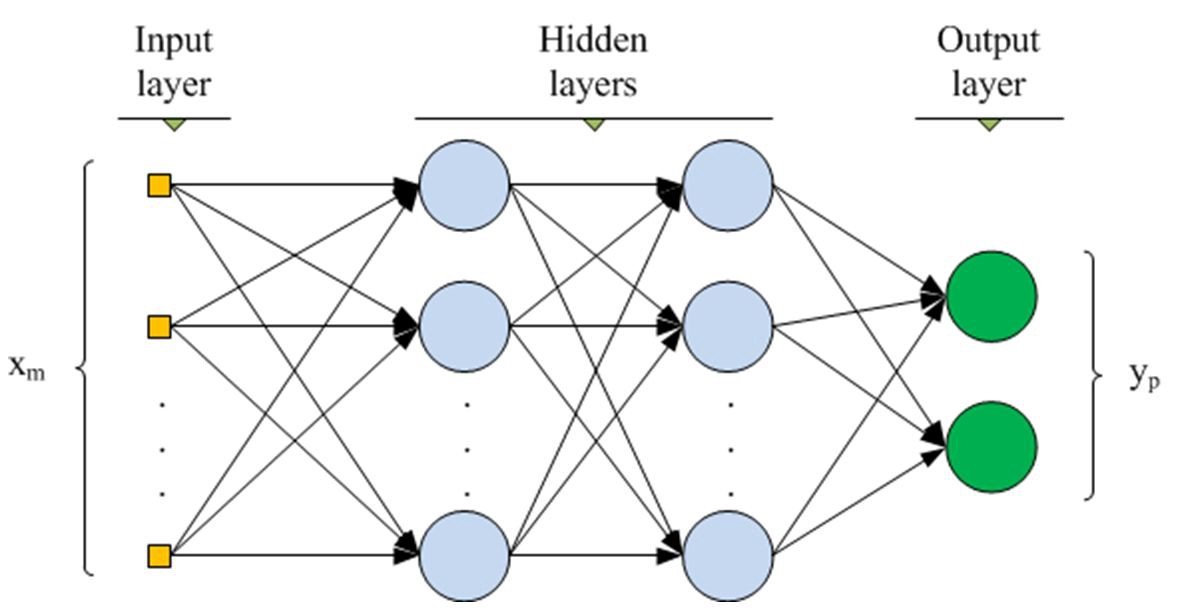
Source: Medium.com
The neural network model can define nonlinear relations between records. Its structure reminds human brain neurons. Model is trained with the help of a labeled dataset, so input data goes through several layers, or the sets of mathematical functions (such models generally use 1 or 2 hidden layers).
Deep neural networks differ from neural networks with the number of used layers: there are many more layers engaged in their work. Deep neural networks provide strict results but need more computing powers and data processing time.
Neural networks are quite good for verifying transactions and insurance claims.
Benefits:
- This approach shows great results in spotting nonlinear and complicated relations in large datasets.
- It works with different kinds of information: transaction data, text, and images that are needed for insurance cases.
- It provides high accuracy in fraud detection.
Drawbacks:
- Neural networks require difficult customization, work of experienced specialists, and powerful computing architecture.
- It is not recommended for all transactions.
- There are problems with interpretation, it can be difficult to understand the way how the system got the solution.
It is a common practice to use a set of models for more clear fraud detection in large enterprises. For example, PayPal implements express assessment with the help of linear modules on the stage of defying regular and uncertain transactions. After that, all suspicious transactions go through the linear model, neural, and deep neural networks.
There is a strict connection between the method of machine learning and such indicators as the type of task, size of the dataset, existing resources, etc. There is no need to choose one of the fraud detection models; to achieve the most accurate solution, data scientists can use several models depending on the situation.